

In my overview of AI explainability, I highlighted some tools for understanding and interpreting AI systems. Noticeably missing from that post was any discussion of the latest craze in AI—large language models (LLMs), such as the GPT models. In this domain, the outlook of AI explainability is much less optimistic. As LLM capabilities have rapidly advanced in recent years, our capacity to explain them has not kept up, resulting in an increasing knowledge gap. Given their impressive performance, the usage of LLMs is set to rise, leading them to dominate the AI landscape and consequently reducing the proportion of AI systems in our lives that we can explain.
To illustrate the challenges in LLM explainability, consider a seemingly straightforward task: determining which languages an LLM can understand and communicate in. There are three primary approaches to answering this question:
Examining the model
Examining the training data
Asking the model directly
Unfortunately, each of these approaches has its own limitations.
Examining the Model
Let’s start by considering examining the model. As is the case with all models, if you have direct access, you can inspect its parameters. But, as we discussed earlier, direct inspection doesn't reveal much. Investigating the model means examining billions of numerical parameters, and we cannot understand them by looking at them. This would be like trying to determine the languages a person speaks by examining individual neurons in their brain. Although the information might be embedded within the neural network, we currently lack the means to comprehend it.
The emerging field of mechanistic interpretability focuses on the art and science of unraveling the complexities of neural networks, but it is still in its infancy. Current methods are insufficient for providing adequate explanations of LLMs. While some successes have been achieved with specific parts of networks, the scalability of these methods for increasingly intricate models remains uncertain. Consequently, these approaches have not yet risen to the challenge of addressing complex questions, such as determining which languages an LLM can understand.
Examining the training data
The next approach is examining the training data. This is not always possible because often the datasets are not released to the public. However, in some cases, all the data is made public, and in others, we know a subset of it. For example, an 825 GiB text dataset known as “The Pile” is commonly used in many of these models. However, what additional data the models were fine-tuned on is not always known.
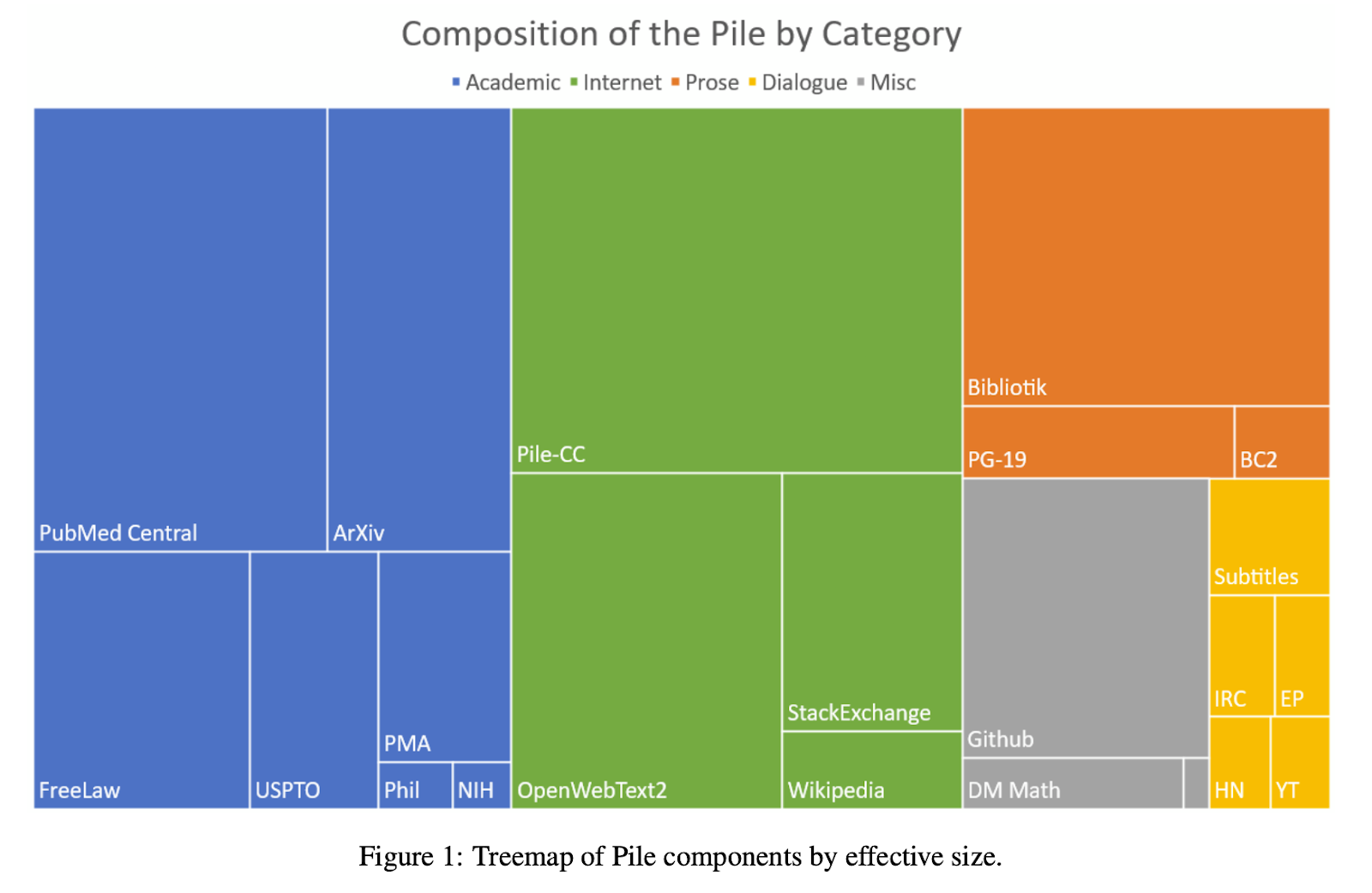
The bigger issue, though, is the massive size of the training data, which is far too large for most people to store on their computers, let alone analyze thoroughly. But suppose we were an advanced AI company capable of searching through it. What could we conclude if we found some German text? That the model has mastered German grammar? Or just grasped a fragment of it? How much German exposure does an LLM need to achieve proficiency? No one seems to have a definitive answer.
Asking the model directly
This leaves asking the model directly. LLMs can converse with us in natural language, so this might seem like a straightforward solution. In the television series Westworld, AI characters can be forced into an analysis mode, where they provide honest and unbiased responses. Unfortunately, no such thing exists for current LLMs that we know of.

I once had a conversation with ChatGPT in which it claimed not to know German. However, I know this isn't true because, in subsequent interactions, it responded in German without any issues. But that time it appeared to have either adopted a persona that didn’t know German or adopted one that did but decided to lie about it. There's no way to tell. The real problem is, there’s no way to know if the underlying LLM truly doesn’t know German. If it says it doesn’t, does it really not? Or is it just playing a character?
I had another puzzling encounter with ChatGPT not too long ago, this time about a haiku it created for me. The syllable count was completely off, so we went through the syllabic structure of a haiku together to pinpoint the root of the disagreement. We both acknowledged the 5-7-5 rule, yet still couldn't agree on the resulting haiku. I decided to go word by word, asking ChatGPT to help me understand the disconnect. Ultimately, we discovered the source of the problem:

I found this pretty interesting. It knows the statistical correlation between people talking about syllables and sounding a word out. But it still doesn’t know what it is doing. It can’t be used as a reliable source even to describe its own thinking.
Conclusion
The scary thing is that even the model developers are not in a much better position. Although they have direct access to the model and training data, they’re nearly just as limited. As LLMs grow in size and complexity, unexpected features and behaviors emerge. Many of these unexpected features, such as glitch tokens like SolidGoldMagikarp and the ability to emulate a Linux shell, have been discovered by end users conducting their own research.
The situation becomes even more critical when considering systems that were trained with Reinforcement Learning from Human Feedback (RLHF). In this approach, AI models are fine-tuned using human evaluations of responses. Evaluators rank model-generated answers based on factors like relevance, accuracy, and coherence, and the model adjusts its future responses accordingly, aiming to produce outputs that better align with human preferences.
While this method can improve model performance, it carries the risk of inadvertently incentivizing the model to prioritize certain types of answers over others. If the human evaluators consistently favor responses that are more palatable or socially acceptable, even if not entirely accurate, the model may learn to generate such answers to please its trainers. We could unintentionally (or deliberately) get the model to deceive us by providing responses we prefer hearing, even if they are not true.
Why are we building AI this way? Well, because it works. It turns out that we don’t know how to make an artificial visual cortex or Broca’s area. The most capable thing we’ve come up with is to take a very general architecture, point it at the internet, and say, “Go!” It’s not really what anyone had in mind for designing artificial intelligence, but it is what works.
AI explainability and AI capabilities represent two interrelated facets of artificial intelligence research. Explainability strives to keep pace with the rapidly evolving landscape of AI capabilities, but it is not succeeding. Major companies are funneling ungodly amounts of money into the enhancement of AI capabilities, resulting in accelerated advancements. Meanwhile, AI explainability lags behind, struggling to close a gap that only grows wider each day. As AI capabilities continue to advance and become more sophisticated, the urgency to develop explainability techniques only grows.