
An Overview of AI Explainability
Opening up the "black box" of AI

Too often people are content to think about modern AI techniques as “black boxes”. Though they can be difficult to understand, this notion is far from the truth. There is an entire subfield of AI, known as AI explainability, that is dedicated to developing techniques to make AI systems more understandable to humans. AI explainability is constantly changing — new AI capabilities are developed that are challenging for humans to understand, and then new explanatory capabilities are developed to help us understand them. This cycle continues as the field of AI explainability works to keep up with the rapidly evolving field of AI capabilities. This post walks through some AI explainability techniques at a level that is supposed to be useful without being too technical.

GOFAI
AI explainability hasn’t always been as difficult. The type of AI developed in the 1980s and earlier, which we now call Good Old-Fashioned AI (GOFAI), relied on clearly defined rules and logical reasoning to make decisions. Decision trees, which involve creating flowchart-like structures to make predictions or decisions based on data, are a classic GOFAI technique. These systems were straightforward to understand, as it was easy to trace the reasoning behind a particular decision. While GOFAI systems were easy to understand, they didn’t work very well. They were limited in their capabilities and often struggled to perform complex tasks or handle unexpected situations. As a result, newer forms of AI, such as machine learning, have become more popular due to their improved performance, even though they are less explainable.

Explainability took a hit as machine learning methods rose in influence. These are the so-called “black box” algorithms. While machine learning has led to more powerful forms of AI, it has not completely replaced GOFAI techniques. In fact, there is significant overlap between GOFAI and modern machine learning techniques, with many newer approaches building upon and incorporating elements of the older methods. For example, decision trees are still widely used in machine learning. However, in the machine learning era, they are often generated by algorithms that analyze data rather than being manually coded by experts, resulting in more accurate and efficient decision trees that are still interpretable and explainable.
Tabular Data
But even for the new techniques, there are ways to explain their results. The specific approach used will depend on the type of data and model. One common type of data for AI is tabular data, which is any data that can be displayed in a table of columns and rows. Examples of tabular data include purchase history at a restaurant, demographic data, and Netflix’s customer data. Models that predict the weather, stock market, or parole decisions use tabular data. Think of it as anything you could open in Microsoft Excel.
SHAP—which stands for SHapley Additive exPlanations—is a popular method of AI explainability for tabular data. It is based on the concept of Shapley values from game theory, which describe the contribution of each element to the overall value of a cooperative game. SHAP values are calculated by considering all possible coalitions of features and determining the average marginal contribution of each feature to the model's prediction.
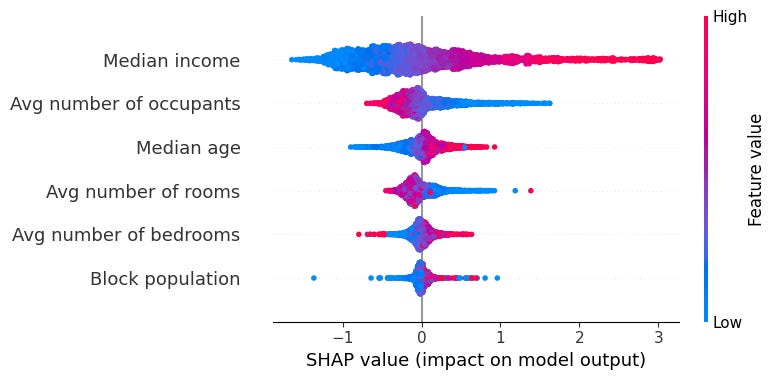
Let's look at an example using data from the 1990 California census. I used this data to build a simple XGBoost model that predicts the median cost of a house in a census block based on features in the data, such as the location, average income in the block, and average number of rooms. The following graph shows the importance of each feature and how it affects the prediction. For example, we can see that as the median income of the block increases, the predicted median house cost tends to increase. However, a higher average number of occupants tends to result in a lower prediction. Some features, such as the population of the block, have a more complex effect on the predicted price.

We can also use SHAP values to examine individual examples. In the figure below, you can see that the base value is 2.072 (in hundreds of thousands of 1990 dollars), and the predicted price was lower, mainly because of the latitude, median income of the block, and longitude.

With models like this, we have complete control over what factors go into them. For instance, if we want to avoid discrimination based on location, we can simply omit location data from the dataset and build a new model. The following figure shows the results of a model that excludes latitude and longitude data.
Here’s the same individual example with the new model:

We got a different value this time. Because we used fewer features, it’s likely to be a less accurate estimate, but that’s a tradeoff that might be worth it depending on the application.
It’s important to keep in mind that excluding features doesn’t always completely eliminate the problem, as certain features can serve as proxies for others. For example, zip code can act as a proxy for race, which can allow racial bias to seep into a model that ostensibly ignores race. Fortunately, there are techniques, such as adversarial training, that can be used to counter this issue. (I won’t go into the details about them here though.)
Computer Vision
Next, we turn to computer vision, the field of using computers to interpret imagery and videos. The models in computer vision are usually larger and more opaque, but, fortunately, there are many methods for explaining their predictions. One common approach is through the use of saliency maps, which are visual representations of the importance of each pixel to the model's prediction. Saliency maps are a way to “look under the hood” and see which parts of an image had the greatest influence on the model's prediction.
This is particularly important because it has revealed the flaws of many models. For example, consider a model designed to distinguish between images of dogs and wolves. One might assume that the model looks for subtle differences in the face and ears. However, it may instead rely on the presence of a collar on the dog or a difference in backgrounds. This might be fine if we know these differences will always be present, but we certainly need to know what’s going on. That’s where saliency maps come in.
I asked a model to tell me what was in a picture and it responded with “tabby cat”. I then used a saliency map technique known as Gradient-weighted Class Activation Mapping (Grad-CAM) to show me where in the picture the model focused, which produced the following image:

Here’s another example where I asked the model what was in the image. It responded with “vizsla” (which I had to google and found out was a type of dog also known as a Hungarian pointer) and “tabby cat”. Then, to open the black box, I used Grad-CAM to show which parts of the image made it think “vizsla” and what parts made it think “tabby cat”.

Another saliency map-based technique is known as Local Interpretable Model-agnostic Explanations (LIME), which looks at sections of an image and determines how that section influenced the model's prediction of a particular class, using green to indicate positive influence and red for negative.


As you can tell from the images above, these methods are not perfect. There are necessary approximations involved in these methods that can throw off the results. They are simply tools that can be helpful when used appropriately. In particular, I’ve noticed that LIME can sometimes provide misleading results, so beware.
Saliency maps aren’t the only game in town for understanding computer vision models. Some new methods drew inspiration from studies on the human brain that found that specific neurons respond to specific people. For example, one study identified a neuron that responded only to images of Jennifer Aniston but not to images of other people. Researchers inspired by this developed a technique for visualizing individual multimodal neurons and identifying which types of images excite a specific neuron.




Below you can see images from the dataset that excited those same neurons.




Overall, I think we have a pretty good set of tools for understanding AI models that work with tabular and imagery data. There are more techniques than discussed here, but I find SHAP values for explaining tabular-based AI models, and saliency maps for explaining imagery-based models, to be the most useful. There is much more work to be done, but I am optimistic that we’ll be able to build upon these tools and develop even more effective methods for explainability. In computer vision, I think we can do more to understand the model’s state in human-friendly terms, perhaps by building on the idea of Concept Activation Vectors.
We haven’t touched on natural language processing (NLP); there are tools (and challenges) there as well, but that’s for another post.