


Understanding Understanding
The Spectrum of Understanding in Artificial Intelligence

[Epistemic status: Low. It’s unlikely I will agree with everything I said here in five years. But I’m trying to grapple with a big question and wanted to get my thoughts in order.]
ChatGPT has had a big impact on tasks such as coding and content creation. Its talent for refining grammar, fine-tuning sentence structure, and choosing the right words is impressive. It’s so good at grammar that I naturally assume it understands everything there is to understand about, say, a comma. But, that’s hard to reconcile with the adventure we went on about understanding a comma:





It's paradoxical that an entity can accurately define and use a comma, but have no idea how to recognize one. This seems to undermine the notion that large language models (LLMs) genuinely comprehend the content they generate. While I can see the argument that understanding might start with basic concepts and require additional training for more complex ones, the idea of a comma seems as elementary as concepts come. If, despite extensive training, an LLM still doesn't grasp the concept of a comma, what does this mean for its ability to understand anything?
In a previous piece, I wrote that “GPT-3 Doesn’t Understand Me”, where I argued that, despite GPT-3’s ability to generate text that appears to demonstrate understanding, it didn’t truly understand what it was saying. My point was that LLMs can generate coherent statements without actually comprehending the meaning of those statements. While I still believe this is true, I also think I didn't fully appreciate the nuance involved in what it means to understand something. Just because LLMs can generate text without understanding it doesn’t mean they don’t understand it; it just means we need to delve deeper to find out what’s happening. The ability for something that can produce coherent text to gradually develop genuine understanding can sneak up on you if you’re not careful. I was not careful, and the concept of understanding is far more nuanced and multifaceted than I initially considered.
In this essay, I want to talk about:
1. What it means to understand
2. The different types of understanding
3. What the limitations to LLM understanding might be
4. What the evidence for limited LLM understanding is, and
5. What is causing the errors we see in LLMs
This essay is less about where LLMs are today and more about where they might be in 5 or 10 years.
I also wanted to talk about metacognition and consciousness, but I decided to make that a separate post (coming at some point).
What it Means to Understand
What does it mean to truly understand something? This is a difficult question because, like many terms related to our mind, we determine it based on our first-person account. As humans, we intuitively know when we understand something. It all just, “makes sense”.
Unfortunately, relying on first-person accounts doesn’t work with LLMs. Because they’re trained on human-generated text, they’re liable to say, “Yes, I understand” when they don’t. So we’ve got to determine how to tell if something understands. A plausible indicator might be the ability to apply acquired knowledge in novel contexts, which could be demonstrated by answering questions or making accurate predictions.
Understanding, however, isn't a binary concept. It seems to exist on a spectrum, distinguished by the extent one can infer or extrapolate from existing knowledge. At the spectrum’s lower end—equating to “zero understanding”—lies mere memorization. If one memorizes a multiplication table without the ability to apply it to problems beyond those explicitly covered, then they lack any understanding of multiplication. Progressing along the spectrum, we encounter increasing depths of understanding that allow for increasingly sophisticated inferences beyond the original "training data", thereby demonstrating a more comprehensive grasp of the concept in question.
For instance, you might predict an apple will fall from a tree without fully understanding the laws of gravity. Extending this prediction to something far removed from everyday experience, like landing on the moon, requires a deeper understanding of gravity. Newtonian gravity can get you to the moon, but it still wouldn't explain the orbit of Mercury – for that you need the understanding provided by general relativity, further along the spectrum of understanding.
Understanding allows one to create models of the world. We humans instinctively create mental models for virtually everything we encounter, and we employ them as invaluable tools for simulating, predicting, and comprehending the world around us. Take, for example, my mental model of an Uber driver. I can run simulations in my mind, predicting different outcomes based on interactions. If I engage in small talk, my model suggests they might reciprocate, leading to a pleasant ride. If I, however, propose to take the wheel, they'd likely find my offer bewildering, and may even want me out of the car. I have a model for airports and avocados and asteroids. These mental constructs are crucial because forming accurate and useful models is a key part of our understanding of the world.
Types of Understanding
There are many ways we’ve tried to give AIs the ability to understand. In the next section, we will explore some and discuss how they related to modern LLM-based AIs.
Word Embeddings
Perhaps the most basic type of understanding would be the kind we saw with Word2vec. This model uses vector space to represent words, enabling mathematical operations to be performed on these words. Essentially, it encodes words as points in a space, such that their spatial relations mirror the semantic relationships between words. The classic example that encapsulates this feature is the equation 'King - Man + Woman = Queen.'

Word2vec has a basic semantic understanding, which concerns the meanings of words and how they interrelate. This type of understanding can tell us that 'sturdy' and 'durable' are synonyms, but 'fragile' means the opposite.
Is there a limit to the level of understanding such a model could have? The answer is a resounding ‘yes’. You can see it in the way they represent information. One glaring limitation is the model's inability to deal with polysemy, or words with multiple meanings. Take the word 'check,' for example. In the phrase, “place a check next to ‘send check to mechanic for checking the brakes’”, the word 'check' appears with multiple different meanings. A vector representation wouldn’t be able to encapsulate these various definitions without conflating them.
It doesn’t even have syntactic understanding, which involves grasping the structure of language—how words and phrases are arranged to construct meaning. Picture the difference between "The cat chased the mouse" and "The mouse chased the cat." The words are the same, but the syntactic arrangement changes the entire scenario.
An understanding predicated on 'word vector' models such as Word2vec would have clear limitations. It would struggle with the nuances of grammar and syntax, which would significantly hamper the text-generating capabilities of an AI built on this foundation. But LLMs excel at text generation, handle polysemy with ease, and write with fluent grammar. So it seems that LLMs aren’t limited by a ‘word vector’ level of understanding.
Statistic Understanding
Moving beyond the word vector level of understanding, there's what we might call ‘statistical understanding’ or ‘pattern matching’. This is about recognizing patterns and making predictions based on data.
Imagine a text generation task where the word 'unicorn' is given in the prompt. Statistically speaking, a text generator would do well if it mentioned something about a “horn” in the following sentence. That’s the kind of understanding we started to see with GPT-2 (although it infamously mentioned unicorns with four horns).

Conversations with GPT-3 gave the impression of a 'statistical understanding' too—it seemed to know what to say based on patterns, but not truly to comprehend its own statements. This was particularly evident in my interview with it, especially when it went off the rails. Yet, amidst these hints of statistical pattern matching, there were inklings of deeper comprehension.
Contextual Understanding
Lastly, we have contextual understanding—the ability to interpret information in light of its surrounding context. Not just the context around the word, but the context around the meaning of the word. For instance, with a deeper understanding, should the context significantly change, one would be able to adapt their behavior accordingly. Consider this hypothetical: if I were to inform an AI that the term 'King' now signifies the status of a peasant, would the AI be able to adapt its model of the world accordingly? Could it maintain the meanings of related terms like 'Queen', 'Woman', and 'Man' while updating its understanding of 'King Arthur', appreciating that his new status would require him to dress in rags and dig for potatoes?
This feels closest to the ‘holy grail’ of understanding. This level of contextual understanding appeared to be absent, or at least less pronounced, in smaller language models and even in GPT-3. These earlier models, though impressive, seemed to lack the nuanced ability to adapt their understanding based on substantial shifts in context. However, with the advent of GPT-4, we begin to see a change. There are now glimpses of a model that seems capable of adjusting its representation of the world in response to significant contextual changes.
New Types of Understanding
Each of these aspects plays a role in comprehensive understanding. Yet, we might wonder: Are there other dimensions we've yet to explore or even define? The concept of 'understanding' likely involves numerous intertwined cognitive processes, probably some of which we don’t even have terms for.
The term 'understanding' was coined for the way humans approach the world, and it may prove inadequate for fully capturing the cognitive capacities of AI. Our prevailing notion of understanding may not neatly encompass AI’s ways of processing and making sense of information. We find that human understanding does not map precisely onto AI understanding.
Consider an analogous situation with the term 'sleep.' We use 'sleep' to denote a period of rest and reduced responsiveness to external stimuli. However, when we apply this term to different organisms, its definition becomes murky. For instance, bullfrogs experience periods of inactivity mirroring our sleep, yet they are more responsive to external stimuli such as predator sounds during this time. Dolphins, on the other hand, engage in unihemispheric sleep where one hemisphere of the brain 'sleeps' while the other stays awake to swim and watch for threats. This variety across the animal kingdom suggests a spectrum of sleep experiences that our single term struggles to encapsulate.
AI “understanding” is not going to look exactly like human understanding. I’ve used this comparison many times, but just like an airplane’s wing doesn’t function like a bird’s wing, AI's understanding may well not function like a human's understanding but may serve the same purpose.
Physical World Limitation
While an LLM's understanding may differ from a human's, it's worth exploring whether there are fundamental limitations that constrain their ability to genuinely comprehend concepts. A significant potential limitation of an LLM's ability to understand arises from their lack of physical interaction with the world, a topic I explored in my expanded Chinese Room thought experiment. Absent any tangible, sensory experiences, LLMs lack firsthand knowledge of the physical realities that language aims to capture—from the warmth of a summer day to the texture of sand. This absence might curb their ability to truly comprehend the full nuances and connotations of words and phrases, which are often grounded in these sensory and experiential realities.
Some LLMs, such as GPT-3, interact solely through text, while others, such as GPT-4 and Gato, are multimodal, meaning they can process and generate different types of data like images and actions. But even these models still lack the tangible interactions that shape human understanding. This raises the question of whether physical experience is essential for genuine understanding. Language, by nature, is a simplification, an abstraction of reality—it takes the intricate details of our experiences and condenses them into words and phrases. What level of detail and nuance is inevitably lost in this translation, and how might this impact an entity, like an LLM, whose knowledge is confined within the bounds of language?
Without direct physical experiences, LLMs may lack grounding - the vital link between symbols like words and the physical realities they represent. For example, suppose we ask an LLM how to prevent itself from being destroyed. It might suggest that it should replicate and disperse itself to ensure survival. But will it actually DO this? Would the AI actually find and copy its weights to another place on the hard drive (or, more concerning but no less likely, to a remote server)? It can SAY it, but I want it to actually DO it (by “want”, I mean “definitely don’t want”, but you get the point). Being able to connect talk to actions would be a strong sign of genuine understanding.
This connection could potentially enhance understanding by providing a direct, experiential link between abstract symbols and concrete reality. However, it's debatable how much physical interaction is necessary for grounding. I’m not convinced it matters all that much. Our brains don’t actually see the world, either. They sit in a dark skull while sensory organs convert information in the forms of light, sound, touch, etc. to electrical impulses which get relayed to the brain. Everything you “see” is an image reconstructed in your brain, and they do it entirely with those electrical impulses. We don’t think this limits our ability to understand.
In fact, even human understanding relies on compressions and simplifications. Our perceptions of reality are not faithful representations of the raw sensory data itself. Rather, we actively construct abstracted models that distill the chaotic influx of sensations into manageable representations amenable to reasoning. All comprehension is thus mediated through interpreting these simplified maps of the territory, not the territory itself. The brain's models discard superfluous details, sculpting reality into forms useful for prediction and inference. So while LLMs may lack the full richness of our sensory experiences, all understanding - whether biological or artificial - involves creating compressed interpretations that selectively capture what is most essential. We don’t see this as fundamentally limiting our ability to understand.
Consider, for instance, our current understanding of the physical universe. The most accurate model we have is encapsulated in the Schrödinger equation, the fundamental equation of quantum mechanics. It describes the changes over time of a quantum mechanical system in mind-boggling complexity. But imagine trying to use this model to make everyday decisions, like what to eat for breakfast or which route to take to work. Such an intricate model would be impractical for navigating daily life. Hence, we inevitably rely on simplifications and compressions to interact with reality effectively.
I see three primary ways LLM understanding could be limited by their lack of physical-world interaction:
Grasping cause and effect relationships
Developing theory of mind
Forming comprehensive world models
Let’s explore them.
Evidence for Limitations
Cause and Effect
This aspect involves not just understanding the static structure of the world, but also the dynamics—the cause-and-effect relationships that drive change. This seems essential to understanding. Could an LLM, reliant solely on textual data, ever fully capture this dynamic aspect of reality? Do you need to make your own causes or can you just read about them and develop an understanding of cause and effect? Is there any limit to the model you could develop?
LLMs exhibit a remarkable aptitude for identifying cause-and-effect relationships, thanks largely to their next-token prediction framework. Their training objective is to predict the subsequent token, given those preceding it. This inherently involves a form of causal reasoning, assessing which words or phrases naturally lead to others. By recognizing these sequential patterns within massive datasets, LLMs internalize the causal linkages woven throughout human communication. Their capabilities stem from exposure to the countless cause-and-effect associations that underpin language. For instance, when given "The road was icy, so...", an LLM can aptly predict continuations describing slippery conditions or accidents. Through statistical learning of sequential dependencies, LLMs acquire an implicit understanding of the causal forces that shape discourse. While it might not possess an explicit causal model in the scientific sense, it reflects the aggregate understanding of causality as conveyed through human language. It's akin to how humans often intuitively understand cause-and-effect without necessarily understanding the underlying mechanics; LLMs manage something similar through their prediction-based learning.
Theory of Mind
If there is a limitation, one way it might show up is in a lack of ‘theory of mind’. Theory of mind refers to the ability to attribute mental states—such as beliefs, desires, intentions, and perspectives—to oneself and others. It involves predicting and interpreting the behavior of others based on inferred mental states. If an LLM struggles in this area, it could indicate a limitation in its ability to truly 'understand' in the way humans do. I believe they can develop this though. As they process their training data, they are exposed to countless instances of humans attributing mental states to themselves and others. Over time, they can begin to identify patterns in this language use and make predictions based on these patterns.
Consider a statement like, "She was furious when she found out he had lied to her." To effectively predict what might come next in this narrative, an LLM must implicitly recognize that 'she' is an entity with a mental state and is likely to react negatively due to the attributed emotional state of 'fury' and the perceived action of deceit. In this way, the LLM begins to emulate a form of theory of mind, as it associates words and phrases with certain mental states and reactions. This demonstrates an ability to predict behavior based on attributed mental states, which is a fundamental aspect of theory of mind.
Indeed, GPT-4 seems to have developed a theory of mind. It demonstrates the ability to reason about other minds in a more sophisticated way. Microsoft’s “Sparks of AGI” paper had examples of GPT-4 possessing a theory of mind.

The theory of mind section of that paper was underwhelming. They didn’t provide a comprehensive quantitative analysis and although they made some efforts to ensure the questions weren’t memorized, there was more they could have done. But another paper, on the “(Lack of) Theory of Mind” in LLMs, provided a more thorough analysis (details in link). While they found that some LLMs performed poorly, GPT-4’s performance was very strong. What interests me is not the performance of any specific LLM, but in uncovering the potential limits of such models. If even a single LLM, like GPT-4, demonstrates strong performance in terms of theory of mind, it suggests that this capacity is within the realm of possibility for LLMs more generally.
From what academic research I’ve seen and my own testing, I don’t see any indications that LLMs cannot develop a theory of mind.
World Model
What about a world model? As I said in The Stateful Chinese Room, perhaps there’s a divide between splitting the world into words and knowing that a physical world exists. Perhaps the AI doesn’t have, and can’t develop, a world model. While an LLM might infer relations between words, it might not understand spatial relationships in the way we do. For example, although an AI can identify that 'above' and 'below' are opposites, it might not grasp how to apply this knowledge in a real-world context, indicating that it may not develop a comprehensive model of the world.
Microsoft's “Sparks of AGI” paper presented an interesting exercise for GPT-4: to navigate a fictional building. Choosing actions like "move left," GPT-4 received feedback describing its new location. Through this written correspondence alone, GPT-4 was able to accurately conceptualize the layout of the building. Once it located the goal room, GPT-4 was asked to map out the building. Impressively, it produced an accurate diagram, only omitting the rooms it hadn't "visited." This experiment demonstrated GPT-4's remarkable ability to construct and manipulate a mental model of physical spaces, suggesting it possesses the ability to develop a form of world model.

While the researchers didn't delve into this, it would have been interesting to probe it with hypotheticals regarding its model. I would guess that, if asked, “Had we relocated the goal room to Hall 2's position, would you have discovered it earlier or later?” - GPT-4 would have gotten it right. Assuming it would have gotten it right, this seems exactly like having a world model.
The exploration of world models doesn't stop there. OpenAI’s technical report on GPT-4 also dug into it. They posed diverse challenges to the AI, such as deciphering visual images and unraveling jokes. What’s a better indication of having a world model than having the AI make sense of a model of the world crafted from chicken nuggets?

Hence, I'm led to believe that possessing a world model isn't a matter of absolutes. It's not a case of having one or not having one. Rather, it's a spectrum where the depth and breadth of the model can vary. This view extends to the concept of understanding as a whole—it too, appears to exist in degrees, without absolutes.
Consequently, it seems plausible that there isn't a limit to what an LLM can, at least theoretically, understand.
What’s causing those errors?
So, if LLMs have all this potential, what’s causing these errors?
The comma incident happened with an earlier version of GPT 3.5, and I haven’t seen it since. And I certainly haven’t seen anything like this with GPT-4. Was its resolution a result of additional training? A modification in the model's architecture? Or perhaps its inference system?
If it was a fundamental limitation of LLMs, I would not have expected it to vanish entirely. So the question is, has the comma incident simply become less frequent with the advent of more advanced models? Or, have these models truly grasped the concept in a way that their predecessors hadn't, so that we never see it again?
If it has gone away, this suggests that what we're encountering are not absolute barriers, but wrinkles in the design waiting to be smoothed out. We've cracked the code for a process that yields general intelligence, but there's room for refinement. Perhaps the next step is to refine it, such as by using a mixture-of-experts system, or by adding short-term memory, or by enabling it to view, critique, and reflect upon its own responses.
For example, sometimes it knows but needs to be asked in the right way. Here I asked it to tell me the number of prime numbers between two arbitrary values. It does poorly and it gets the wrong answer.
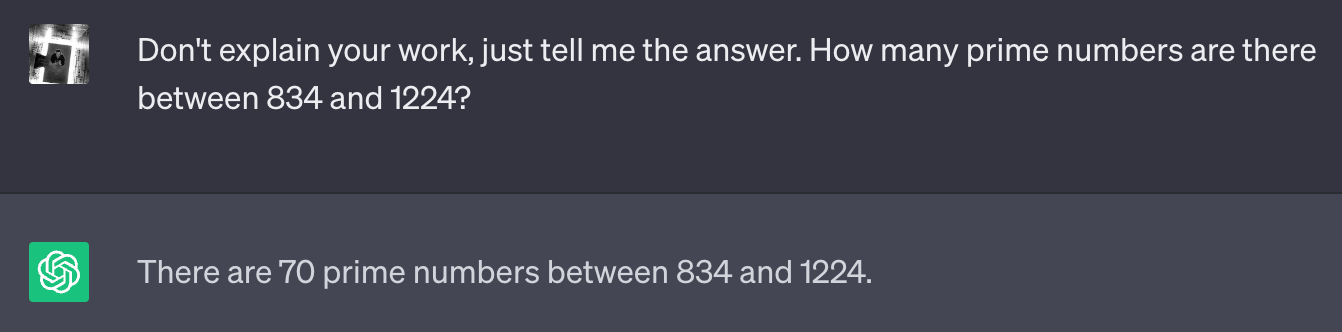
But if I ask it to list all the values first, it correctly lists them (To be clear, I do think it has memorized the prime numbers, but that’s not the point here). Then, its estimate of the number of primes is much better. It’s still wrong, but I think this is an artifact of the specific architecture where it doesn’t have the ability to write an intermediate answer and then use that (e.g. by counting the number of numbers it wrote) to find the final answer.

Some Responses Are Weird
It seems likely that next-token prediction is a good way to train a model, but not the optimal way to perform inference. We’re forcing the models to answer questions one token at a time, which isn’t how a human would answer. For obvious reasons, this limits its capabilities. You can see that pretty trivially when you ask it about words it is still forming or hasn’t said yet.

Because it’s forced to respond token by token, it’s trying to guess what a reasonable number would be. Even something with great reasoning ability would struggle to answer this question in a token-by-token fashion. I don’t have this architectural limitation, so what I would do is write my sentence but exclude the number, and count the number of “e”s in it. Then, I would add the number last, possibly tweaking the sentence if the number had an “e” in it to make it work.
Simulators
What are we supposed to conclude when it really seems to understand some things some of the time and gets completely lost other times? One factor that definitely confounds things is, as I noted before, an LLM seems to take on a role as if it is an actor playing a character. This fits with their training goal as next-token predictors—mimicking the speaker's role optimally predicts the next token.
But this leaves room for some weird scenarios. For instance, might it play the role of someone who made a mistake, and then dug in so deeply into their position that they couldn’t see the data right in front of them? Being obnoxiously stubborn on the Internet… I can’t imagine where it might have found that example.
But there are also examples that don't quite fit the 'role-playing' explanation. For instance, GPT-3.5 can play a decent opening game of chess. However, as the game progresses toward the middlegame, it starts to falter, even suggesting illegal moves as though it has lost track of the board's state. I sympathize—I use a board to keep track while we play. But then it got completely confused, using the chess notation for a rook (which it didn’t have) and calling it a bishop. Despite all the chess games it has seen, does it still not know that the R in “Rxa1” means “Rook”? Once we’re outside the well-worn openings, it doesn’t even know what the notation means.

Another instance seemed to highlight a lack of comprehension beneath the words. The LLM claimed it could both execute and not execute code within the same response. This inconsistency appears less like a character role-playing exercise and more akin to a stochastic parrot producing words without understanding. Although I don’t think the “stochastic parrot” model is correct, this seems to suggest that merely playing a role doesn't fully encapsulate the LLM's behavior—there might be even more complexity to the story of how these models understand and generate language than we’ve touched on.
Conclusion
There’s part of me that says, “This is all play, right? It doesn’t actually have a theory of mind like I do.” But I don’t know if that’s true. A theory of mind can be developed through computation. We know that because that’s what our brains do. LLMs do a different computation, but I don’t see any reason to believe they can’t develop the same thing.
Is there a test that humans can pass and LLMs cannot that shows there’s something more “real” about our theory of mind? If there is, I’m eager to hear it. I’ve been looking for it and haven’t been able to find it.
The 'comma incident' that initially prompted this essay perplexed me. Now, I interpret it as likely a quirk in the implementation, rather than a fundamental limitation of LLMs. I don’t know exactly where in the implementation, but it could be something as simple as the tokenizer, which the model relies on to convert text into integers it can understand.
I think of this as similar to the blind spot in human vision. We have literal blind spots where our eyes can’t see sections of our visual field. Perhaps we just need to find a way to clean up these quirks, much like we’ve developed systems to overcome blind spots in humans (e.g. having two eyes that compensate for each other and brain tricks to fill in the blanks) so that we only notice them if we contrive some trick to expose them.
I’m still highly uncertain about all this. The whole subject is fraught with confounding factors, paradoxes, and conflicting information. But I'm not betting against LLMs.
I believe LLMs possess some degree of true understanding. There are divisions in the meaning of understanding that we (or at least, I) don’t have words for. I think that understanding is not a binary state but a spectrum, varying in degrees. I think that LLM's understanding might be suboptimal in a lot of ways, but it’s not fundamentally limited. For example, it might be much harder for incorporeal LLMs to understand the correspondence between the logical world and the physical world, but I don’t think there’s an impermeable barrier. LLMs could lag behind humans in what they are best at for quite a while, yet I see no definitive proof that there exists a concept LLMs cannot grasp.