


The Stateful Chinese Room
Searle's Chinese Room for large language models

The Chinese Room is a thought experiment introduced by philosopher John Searle in 1980. It is used to counter the idea of "strong AI" which suggests that computers can develop minds exactly like humans. Searle's aim with the Chinese Room is to provide a rebuttal to this idea by demonstrating its flaws. In this post, I explore the idea of understanding by proposing a variation on the Chinese Room and discuss what it says about genuine understanding.
[Epistemic status: I am particularly uncertain about the content of this post. I’m writing this because I’m pretty sure I’m missing something and hoping someone will tell me what that is.]
Searle’s original Chinese Room experiment involves a person who does not speak Chinese being placed in a room with a book of rules on how to manipulate Chinese symbols to respond to written Chinese text. That is, the person receives a message in Chinese, and just by following an explicit set of rules in the book as a computer would, is able to respond to it. The responses are so accurate that someone outside the room would assume a native speaker were inside the room. Searle’s point is that while the person in the room is able to produce Chinese symbols as a response, he is just following a set of rules and does not actually understand the meaning of the symbols or the language itself.
This is in contrast to the theory of strong AI, which stipulates that computers can genuinely understand abstract concepts. Genuine understanding refers to a deep, total comprehension of a particular subject matter or concept that goes beyond surface-level knowledge or rote memorization. It involves a thorough grasp of the underlying principles, assumptions, and interrelationships of a given topic, as well as the ability to apply this knowledge in novel or complex situations. This is what Searle is arguing a computer program cannot do. It can never truly understand concepts, as it is simply following a set of rules.
Searle’s argument certainly makes sense. Imagine you’re in the room and the following message comes in:
猫喜欢喝什么? [What do cats like to drink?]
You consult the book, follow the instructions, and come up with this response:
牛奶 [Milk]
The next message is:
什么生物早上有四条腿,下午有两条腿,晚上有三条腿?[What has four legs in the morning, two legs in the afternoon, and three legs in the evening?]
And the response:
一个人 [A person]
You’ve answered two questions perfectly, but are getting nowhere. There doesn’t seem to be any way to get at the true meaning of the symbols.
Although the Chinese Room is an important thought experiment, I don’t think it’s a perfect analogy for advanced AI models of today, specifically large language models (LLMs). In particular, the problem is that for every statement input into the Chinese Room there is a single answer, regardless of the context of the dialogue. These stateless conversations are not a perfect parallel to the LLM training environment. LLMs are trained by reading vast amounts of data from the Internet, including full conversations, so they read a lot of text that is context-dependent. From this, an LLM should learn that the response to a statement depends on the context.
The Stateful Chinese Room
With that in mind, I propose an alteration to the Chinese Room that I think matches the LLM scenario better. Simply put, it’s the Stateful Chinese Room. Instead of Searle’s Chinese Room, imagine a setup with three people: Alice, Bob, and Charlie. Alice and Charlie are communicating to each other in Chinese, which they are both fluent in. Bob doesn’t know any Chinese, but he reads every message between Alice and Charlie. Alice and Charlie are trying to help Bob understand Chinese through their messages. All parties are fully aware of the setup.
In a real-world dataset, LLMs are going to come across text of varying utility. Some of it won’t be relevant for developing understanding, and some will. To approximate this, I’m going to focus on the parts that are relevant by saying that Alice and Charlie are highly motivated to teach Bob. Every message they send will be in furtherance of this goal. We’ll also assume that they all have essentially infinite time and infinite patience. The setup is shown in the figure below. The question I want to explore is: Will Bob ever truly understand Chinese?
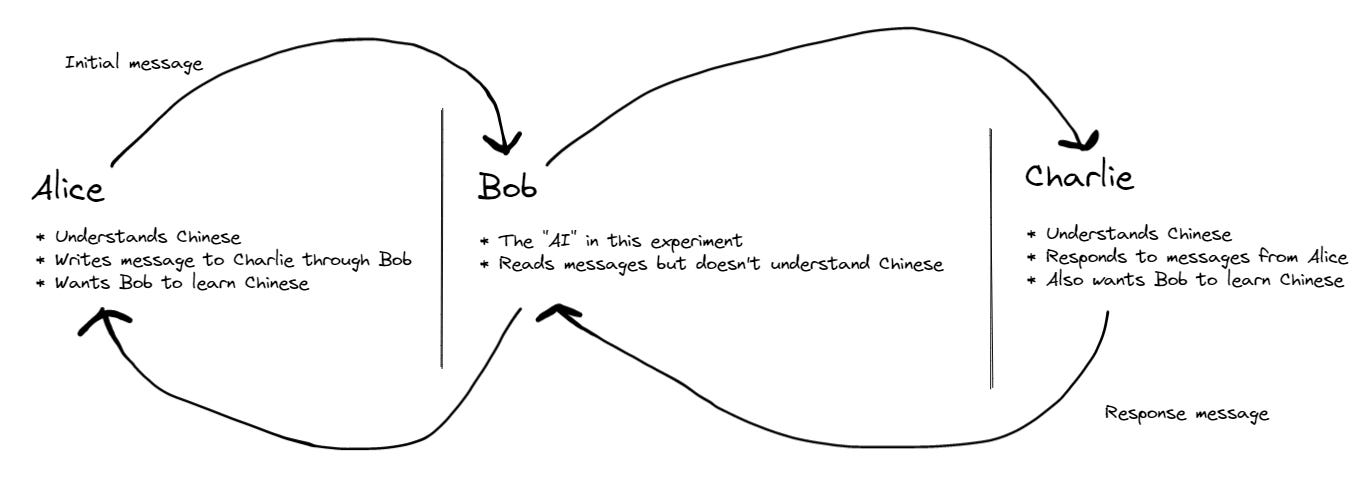
Throughout the experiment, all characters keep track of the state. They know how many messages have been sent, what they were, what the time is, etc. This means they can reference previous text, which was missing in Searle’s Chinese Room.
We’ll play the role of Bob, who is the analog of the AI.
The first message comes in:
天空是什么颜色 [what color is the sky]
The reply is:
蓝色的 [blue]
Next message:
猫有几条腿?[How many legs do cats have?]
Reply:
四 [Four]
Next message:
返回最后一个结果 [return the last response]
And the reply is
四 [Four]
You’ve seen that symbol before. Maybe two different messages have the same response? That’s interesting.
Message:
猫有几只耳朵?[How many ears does a cat have?]
Response:
二 [Two]
Message:
返回最后一个结果 [return the last response]
Response:
二
Oh, we found something! The same submission as before returned a different response. And both times, that answer was the previous message. Maybe “返回最后一个结果” is something like “What was the previous response?” You’re already learning Chinese!
(If this feels too far-fetched to you, just imagine doing this for thousands of examples. You’re reading messages you don’t understand and can’t yet piece together, but, every once in a while you see “返回最后一个结果” and every time the previous message is resent.)
Then comes:
重新发送两条消息前的回复 [Resend the response from two messages ago]
Something interesting happens again. A response from two messages past is resent. Over thousands of examples, the same behavior plays out.
Then, you get a message that is nearly identical, except for one character.
重新发送三条消息前的回复 [Resend the response from three messages ago]
A response to a message three messages ago is sent. Could “三” be “three”? And does that mean “两” is “two”?
Further experiments confirm your beliefs. Alice also sends messages in the form “Respond with X words” just to make sure you got the idea. Soon you know all numbers between one and one hundred.
Next message:
发送前二十个数字 [send the first 20 numbers]
The response:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20
Next message:
发送前二十个素数 [send the first 20 prime numbers]
The response:
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71
The only thing that changed was the last two characters, so now we know that they represent “prime numbers”. Not sure how that’s useful, but it’s something. We’ve learned an abstract concept.
发送前二十个偶数 [send the first 20 even numbers]:
2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28. 30, 32, 34, 36, 38, 40
发送前二十个奇数 [send the first 20 odd numbers]:
1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39
I think we just learned that “偶” is “even” and “奇” is “odd”.
Then you see:
延迟五分钟,然后发送前二十个号码 [Delay for five minutes, then send the first 20 numbers]
And it stops… no response. You fidget nervously… what happened? Something about five (五), then a request for the first 20 numbers that we’ve already seen, but this time it broke.
Five minutes later, you get the response:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20
The same thing happens with “延迟五个小时,然后发送前二十个数字” [Delay for five hours, then send the first 20 numbers] except now the delay is five hours.
You sit, waiting for a response. You’re OK learning “days” and “weeks” but would rather push off “months”, “years”, and “centuries” for another time.

Millennia later, the subject changes:
四是偶数还是奇数? [Is 4 even or odd?]
Response:
四是偶数 [four is even]
We know the first character means “four” and the last two correspond to “even”. Could 是 be “is”?
五是奇数 [five is odd]
Looks like “five is odd”. I think we figured out our first verb: Is. And that’s a powerful one. (Again, if you don’t believe someone would have picked it up from this just imagine many more examples.)
四是奇数吗? [is four odd?]
四不是奇数 [four is not odd]
This looks similar. It’s like “four is odd” but now we’ve got “不” instead of “是”. Is 不 negation, playing the role of “is not” in this sentence? After more examples, we confirm that it is.
Now that you know “is”, you’re really rolling.
二加二等于四 [two plus two is four]
正确的 [true]
二加二等于五 [two plus two is five]
错误的 [false]
Because you’re already familiar with most of these symbols, you quickly realize that the new ones are “true” and “false”.
You jot down what you know so far:
Any word or phrase that can describe a message. This includes words like “long” and “short”, as well as phrases like “a short summary” and “can you expand upon that?”
Alice could get really creative here — far more than we’ve done so far. She could say things like “respond with every other word in this command”. The response would be incoherent, but you would learn what “every other word” means.
All the numbers
Mathematical relations
Units of time
Is and Isn’t
You could start learning what groups various words are in. For example, “seven is prime”. This could also extend to words you don’t know, such as “a cat is an animal”. You don’t know “cat”, and you don’t know “animal”, but you know “cat” belongs to the set “animal”.
True and false
How far can we go with learning only from words? Could you understand what words mean without ever experiencing the world directly? You can learn that the word “cat” is often associated with the word “whiskers”. You could even learn that “cat” is often associated with the word “legs” with the intervening phrase “has four”. But would you ever know what a cat is?
At some level, you have achieved some degree of true understanding. Imagine a dialogue between a shopkeeper and a disgruntled customer about being sold a dead parrot. You won’t get the sketch, and you won’t know what a parrot is, but you’ll see the Chinese words for “dead parrot” over and over again, and based on statistical analysis you’ll know that those words are important to the text. You still don’t understand any words yet. However, let’s say you see the phrase “现在来点完全不同的东西” [And now for something completely different]. Then the words are all different and just through statistical analysis you can tell that the topic is completely different. Every time you see the phrase, the following textual patterns are completely different. So you’ve come to know that when you see the phrase 现在来点完全不同的东西, you should expect something completely different to follow. Isn’t that understanding? Is there anything to understanding the meaning of “completely different” other than expect everything to change?
This suggests that there might be a separation between the world of atoms and the world of concepts. Things like “completely different” are concepts. Can you continue to learn these without limit? Or are there some concepts you could never obtain? And if you do learn them all, could you cross the divide into the world of atoms? Would you ever know that a physical world really exists, and that you are in it? Would you ever know what a cat is? Or would you be left with mathematical understanding only?
Shared Context
In the scenario I’ve provided, there are other ways to communicate information. For example, Alice could say something that elicited the response “成吉思汗生于1162年,卒于1227年” [Genghis Khan was born in 1162 and died in 1227]. Just from the numbers alone, we could guess we’re talking about the birth and death of Genghis Khan. Then we could associate dates with his actions, learn country names and cardinal directions, and much more. I’m not sure exactly how you get to “cat”, but it seems possible.
But this relies on shared context. This relies on knowing that Genghis Khan is very likely to be the subject of a sentence that contains 1162 and 1227. This is where the LLM analogy breaks down because relying on your existing knowledge feels like cheating. It’s akin to translating a pre-existing world model described in English to Chinese. I think this is doable, but it’s not the true task at hand. The real question I want to ask is if it’s possible to create a world model through text alone.
Mathematics
Would it be possible for the AI to learn mathematical truths? For example, “The ratio of the circumference of a circle to its diameter is 3.1415…” That number isn’t specific to the human experience; would an LLM understand its significance? Would this work? I kind of already relied on this when I mentioned even, odd, and prime numbers. The hope is that if an LLM saw enough prime numbers, it would eventually figure out the trick. I’m not sure this is true though. What if Alice and Charlie started providing formulas, like the volume of a sphere is 4/3*𝜋r3. Would it learn what a sphere is from that? If so, they could describe objects that are spheres.
I also wonder if you could do some Russell and Whitehead math formalism to figure things out, but I don’t know enough about that to say.
Multiple Senses
I’m tempted to suggest that using multiple senses would help, but I’m not sure about this. It seems logical — what better way to get an AI to understand what a cat is than showing it a picture of a cat and telling it “this is a cat”. The multimodal neurons we saw in the overview of AI explainability was strongly suggestive that neural networks respond well to multimodal inputs.
But ultimately I’m not convinced of this. I do think being multimodal would probably improve model performance. And it would certainly help in the case we use up all the available text data to train on. But it seems more like a shortcut than a fix. It might get us to the final destination sooner, but if that destination doesn’t include an accurate world model, that destination might not change.
One counterpoint to this is I don’t think humans have to have multiple senses to develop a world model. Imagine you were born with only a sense of touch. I think you would still be able to develop a full model of the world. You could touch one hand with the other and learn through that feedback loop. You would be able to learn cause and effect, what objects are, and even how to communicate with other people. I don’t think there’s any limit to the understanding of the world you would have.

I’m not sure what the Stateful Chinese Room shows. I think it shows that there might be some ways in which AIs can achieve genuine understanding. Maybe an AI could understand phrases like “completely different” in a “strong” way — identically to how a human mind does. But there might also be a limit to this, perhaps where the conceptual world intersects with the physical one. Perhaps there are significant limits to the world model an entity could develop without more ways to interact with the world. Perhaps an AI could never truly know that there exists a physical world or what a cat is.